
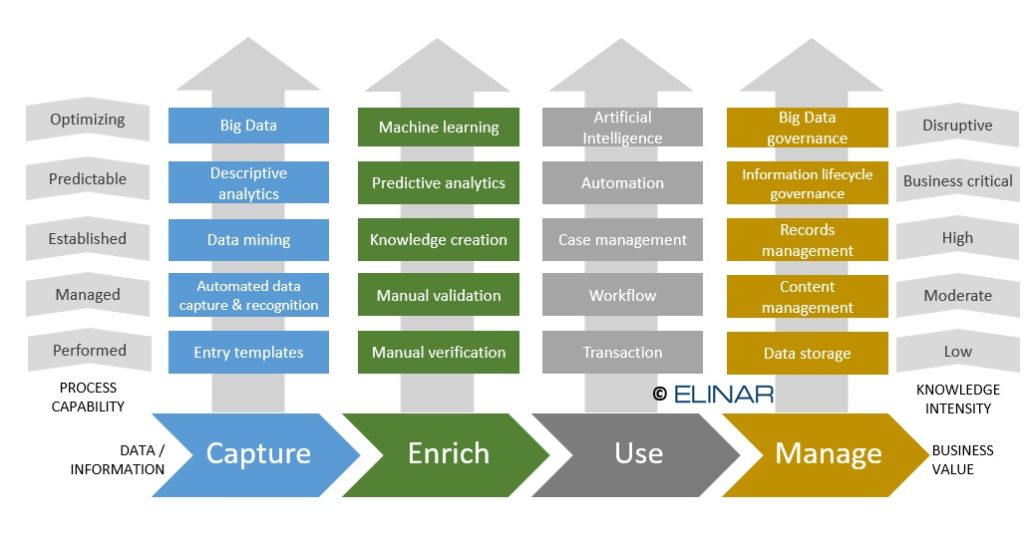
We deliver end-to-end content and information management services that allow you to take every step from capturing to managing your critical business data. You can refine your data and information into business value by going through the following phases: 1) Capturing, 2) Enriching, 3) Using and 4) Managing.
Background

- 40 000 000 000 000 000 000 000 bytes of data – By the year 2020 we the world will have 40 000 exabytes of data.
- In 2012 there was only 0,5 % analyzed data from all the World’s data.
- Even 80 % of business data and information is unstructured. It is data that doesn’t have a pre-defined data model or is not organized – and thus is unusable for business.
- That means even 32 000 000 000 000 000 000 000 bytes of business potential.
- Unstructured data and information are irregular in its form and thus it basically cannot be processed for business benefits.
More extensive information, more capable processes
There are five levels of process capability for each of the four phases: 1) Performed, 2) Managed, 3) Established, 4) Predictable and 5) Optimizing.
- You can perform each phase manually, but that is resource-consuming and extremely inefficient – especially when the amount of data or the size of your business increases.
- It is possible to manage each phase – but this means taking one step beyond performing wholly manual tasks. It requires automation, workflow definition, and content management practices.
- After that, you can establish capabilities, from data mining to knowledge creation – and from case management to records management.
- Predictable process capabilities enable your business to take a step toward powerful analytics and automation. This enables you to progress to cognitive business.
- As the increasing complexity of your information starts to become disruptive, process capabilities become more about optimizing your business. Big Data, machine learning, artificial intelligence, and information governance are the key solution areas here.
CAPTURE
Turning data into business value begins by capturing it.
At first, we can use manual entry templates, but as the number of data increases, we need automated data capture and recognition. Automatic data capturing and recognition (or identification) means automatically identifying objects, collecting data from them and entering it to computer systems. And all this without human involvement. A basic example would be an invoice. There are many ways to do this and our solutions are mainly focused on optical character recognition (OCR). It is suitable for printed text recognition.
Unstructured data challenge
There is structured data such as tax returns that have always completely same structure. This data is the easiest to capture and doesn’t need special applications. However, the majority of data is in semi-structured (such as invoices, purchase orders) or unstructured (such as letters, contracts, articles) form. This data might have various appearances. Or the data form can be completely flexible. Semi-structured and unstructured data needs, after all, special applications and solutions to be captured.
As the data capture process becomes established, we can implement data-mining solutions and practices. After that, we can also consider using descriptive analytics–statistics that describe your collected data. At this stage, we can implement neural networks, technologies such as IBM Big Insights and various artificial intelligence approaches.
Delivered solution
We have delivered capture-phase solutions for such organizations as the large Norwegian car service company, Bertel O. Steen (BOS).
ENRICH
Before you can really use your data, you must enrich it.
Manual verification and validation are the first steps for this process, but they can soon become too resource-consuming.
- Data verification = your data is in the correct form and that it contains no errors.
- Data validation = figuring out the qualitative aspects of the data at hand. And also determining how well it suits your purposes.
After that, we can move you on to the knowledge-creation phase, in which your validated data is enriched further into actual organizational knowledge. So the data becomes information after it has been analyzed. Knowledge is what we get when we have a lot of experience with information on a given subject.
Beyond that, we can apply predictive analytics, which is much more than just descriptive analytics. With predictive analytics, we analyze historical and current information in order to predict the future.
USE
Basic transactions are the first way to use your business data.
As the depth of your organizational knowledge increases, you need more sophisticated solutions: case management practices and ultimately AI. As the amount of data and its complexity increase, you should implement workflow practices. After you have established workflow, you can implement case management practices for you that transform parts of your business operation into manageable cases.
Your information may become even more complex; then, your next step is making use of automation. Ultimately, you can employ powerful AI systems can for utilizing your data and transforming it to become much more efficient.
Delivered solutions
- We have delivered many solutions for using business data. For Blueprint Genetics we’ve delivered a whole structure for workflow, case management, and automation.
- The quality control system at the City of Lahti, Finland uses our case management solution; so does The Employment Fund of Finland.
MANAGE
Perform data management at its basic level with data storage.
As information complexity in an organization increases, there is a need for more robust content and records management. In the end, you need to implement the whole package of data governance solutions. Also, maintain your focus on the entire life cycle of your information.
Delivered solution
- We have delivered a comprehensive records management solution for example for Mutual Insurance Company Ilmarinen.

Ari Juntunen, CTO
+358 40 524 4482