
ElinarAI has been very successful in past years on solving various different unstructured data related challenges, including Accounts Payable / Sales Order Automation, Medical Records Sensemaking and various Legal Issues like GDPR/Privacy and automated analysis of Legal Cases.
Our Initial approach was to combine highly advanced ElinarNER (Elinar Named Entity Recognizer) with Deep Learning to maximize accuracy of the model with reasonable amount of training data. This does provide highly accurate results when working with large enterprise customers who typically can provide large amount of training data. For example, a global company is able to provide 2 million invoices from past 2 years to create highly accurate AI that automates all three critical pain points in Accounts Payable process:
- Preparing Invoice for Approval (Line Item Detection)
- Generating Invoice Posting (GL-Account code, Cost Center and so on) Information and
- Provide all necessary information (like non-deductible VAT) to upload invoice into accounting system
Having 2 million long invoices will result somewhere between 5-20 million line-items in the training data set; accuracy and automation level will be very high. Unfortunately, not all problems have this high level of prepared training data.
A good example of manual training data generation can be found from legal field. Consider a legal expert system working with authority issued decisions that are 40 pages long. For traditional supervised training AI to be able to make sense of them, a Legal Expert must manually analyze large number of decisions. Manual preparation is needed for AI to be able to fully understand and generalize the specific legal domain it is trained to work with. This manual labelling forms a significant barrier for advanced automation. Employing an army of experts tends to be quite expensive. Let’s assume that it takes two hours for a Legal Expert to fully analyze a decision. To reach sufficient accuracy, it is possible that 10 000 prepared decisions are needed; That is 20 000 hours of highly trained legal professional. At 200 € / hour this translates to 4 000 000 € expense and will take significant calendar time. Resulting Legal Expert System will be quite expensive; There is not going to be may business cases where such expense can be justified.
Deep Language Models
Deep Learning Models are quickly changing how much training data and effort are needed to develop AI that understands business problems. Deep Language Models can be trained using vast amounts of open data. Instead of starting with AI development by annotating 10 000 or 2 000 000 samples of specific domain training data (like Invoices or Legal Decisions prepared by humans) we first train a generic AI that understands written text very well. Deep Language Models acquires this capability by learning from countless samples of text.
Deep Language Models are trained Unsupervised. Training a language model is a matter of acquiring appropriate training data and then using Deep Learning framework like ElinarAI to train Language Model with the data. This is simple and “neat”; provided sufficient training data these modern models can learn nearly anything.
Recently the language models have grown to be extremely large (like Nvidia Megatron-BERT with 17 Billion parameters or OpenAI GPT-3 with 175 Billion parameters). Large size of these models presents a serious real-life issue; a large model is slow. Really slow. If a simple query to the model takes 30 seconds, imagine what crawling through 100s of terabytes of data to find GDPR information will take.
ElinarAI has adopted a slightly different flavor of using Language Models. Instead of aiming for huge all-encompassing model we have adopted an approach where we develop domain specific language models. They can be much smaller and thus much faster.
Careful training data selection generates AI models that are safe to use. For example, a chat bot based on medical language model must not suggest for mentally ill patient to commit suicide, as has been reported to happen in a case with a general model that had been trained with all of the internet. Reckless use of data sources is serious issue with unsupervised training that can only be alleviated by careful selection of training data.
Deep Language Models may utilize large data sets including Big Data sources. Using Legal Domain as an example, training data would contain a subset of Wikipedia, local legislation, court issued case texts and other text like governmental and parliamentary background material. Domain AI in this case would be trained with ~10 Gb of pure textual data of general and domain specific nature. This will yield a Language Model that is able to understand general text (based on Wikipedia) and also have a deep structural understanding of legal language and relevant legal ontologies.
Elinar participates in research to develop optimum strategies for domain training data selection. Selection affects underlying structure and ontologies AI automatically constructs. This will have significant impact on resulting AI’s capabilities to solve real life business issues.
Deep Transfer Learning
Deep Transfer Learning is a process where a Domain Specific AI model is fine tuned to fulfill a specific business task. In previous example a Legal Expert had to manually annotate 10 000 cases for AI to be able to grasp the fine details in the legal rulings. Instead of using 10 000 cases we will need to annotate only 500 (this is 5% of total) cases and leverage the knowledge contained within the Language Model.
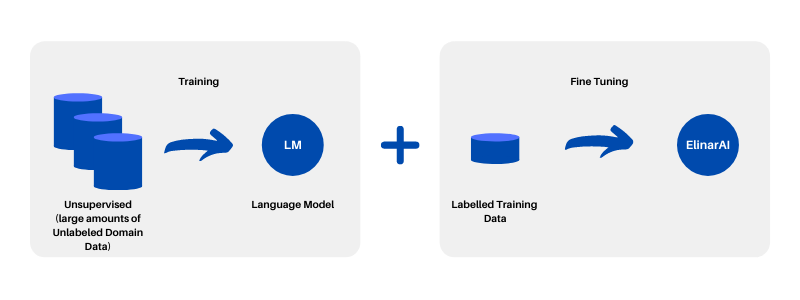
ElinarAI
ElinarAI transfers domain understanding that a language model has created using specific training data to resulting AI. This way we can leverage large carefully selected data sets that have been learned by Language Model and use this to “bootstrap” a specific AI.
Our experience is that by using Deep Language Models to bootstrap specific AIs (like Privacy or Legal) will have significant impact on resulting AI accuracy.
This allows us to give computer cognitive capabilities that are very close to human in domain specific tasks. ElinarAI deletes unnecessary human labor from the loop. This yields increased accuracy and productivity.