
Introduction
ElinarAI is a premiere Deep Transfer Learning based AI solution to automate common business tasks that traditionally have required human cognition to automate. ElinarAI focuses on Document Understanding and is based on a paradigm called Deep Transfer Learning (DLT). In DLT the basis is a Language Model that has been pre-trained to understand a human way to use language and capture much of the common knowledge humans rely on to understand the context and make conclusions. The model is then fine-tuned on a relatively small number of samples to fulfill a business need. ElinarAI is commonly embedded into our Business Partners’ solutions to add brains into them.
ElinarAI consists of:
- ElinarAI Miner – User interface to train, validate and manage data and related workflows and to generate reports in a highly secure and intuitive environment
- ElinarNER – High Performance Text Analytics Engine
- Deep AI – Deep Transfer Learning trained (TensorFlow) AI model
ElinarAI LMs are all strongly geared towards two core ElinarAI functionalities that are commonly needed by our customer base: Data Extraction and Document Classification. Pre-training process trains language models to understand human-used language and these two core functionalities. Some Elinar Language Models are considered Large Language Models (LLMs). There is a sharp increase in Inference time when the model size grows. Elinar has spent significant R&D effort to change LM pre-training for better to sort our customer base needs.
Elinar Language Models should not be confused with much-hyped regenerative “GPT” style models that are very good on generating text. As our goal is not to generate text but extract and classify documents, it is much more efficient to use model capacity in pretraining towards these objectives rather than generating human friendly dialogue.
ElinarAI model training pipeline utilizes two major steps: Language Model (LM) Training (Unsupervised Learning) and customer specific Fine Tuning (Supervised Learning).
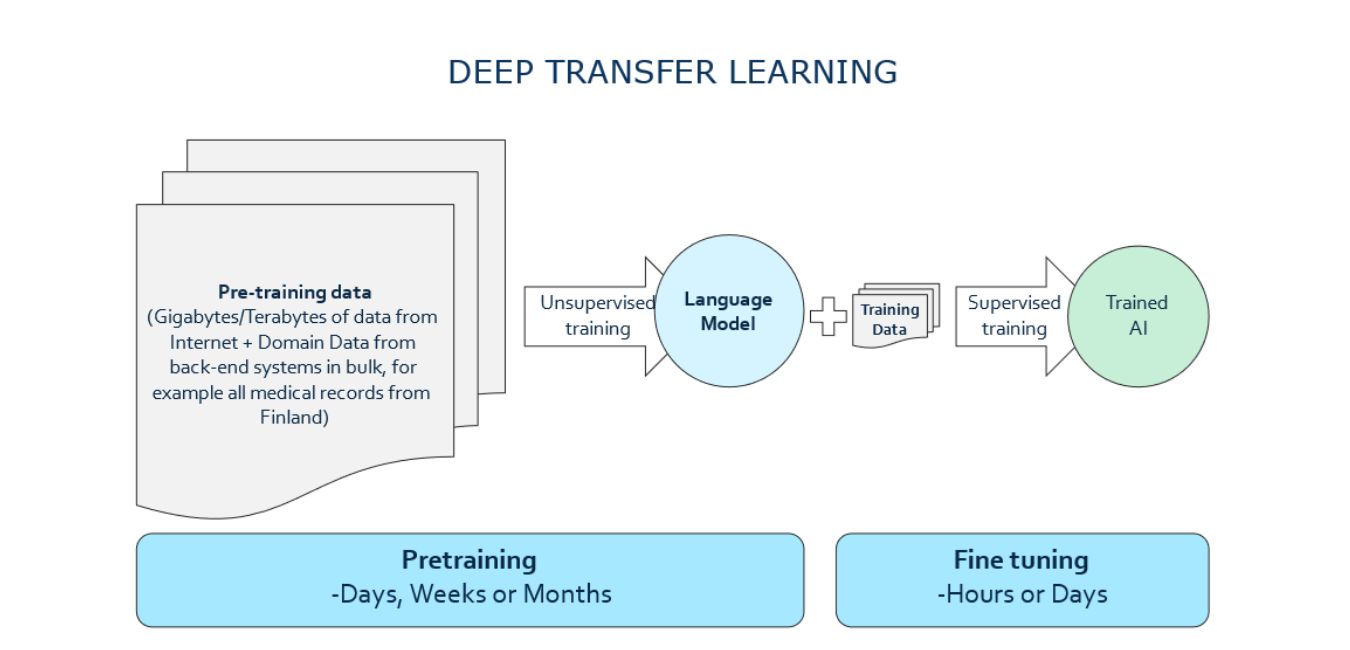
This document focuses on the Fine-Tuning aspect, specifically on how base model and training data selection affects the outcome.
ElinarNER
ElinarNER is Elinar developed high-performance traditional Text Analytics engine that is used to prepare textual data for Deep AI analysis. ElinarNER heavily pseudonymizes text and makes it very difficult for humans to understand but enables AI to learn and analyze textual contents much more efficiently.
Data Curation
ElinarNER + several in-house developed data curation techniques help us to enrich the training data, eliminate unwanted samples and ensure industry leading privacy protections on massive data sets. Elinar Data Curation practices eliminate ~12 % of the samples (except for Swedish where over 25% of samples are discarded) AND heavily pseudonymizes data to ensure privacy.
Data Curation makes training data more relevant to our objectives while removing unwanted knowledge from training data. In our experience a smaller model with well curated data will achieve a similar or better accuracy than larger model trained on non-curated data. Relying on curated and cleaned data sets for pre-training will both increase accuracy and decrease pre-training cost.
Language Model Selection
Elinar pretrains and makes pretrained language models available for customers and partners to make use of.
There are several dimensions on selecting base language model that are:
- Languages pretrained into the model
- Model Accuracy
- Model Speed
Accuracy and Speed are somewhat mutually exclusive; larger model is generally more accurate but slower.
Pretrained Languages
Elinar uses strongly modified T5 objectives to accomplish state of the art LM/LLM performance on Data Extraction and Document Classification tasks. In order to support speedy
Elinar has several pretrained models available immediately for usage. Following models are currently available for immediate consumption:
- SV/FI/NO/EN
- SV/FI/NO/EN/PT/ES
- SV/FI/EN/DE
- SV/FI/EN/DE/FR
- SV/FI/EN/FR
- SV/FI/EN/IT
- FI Medical
- ES
- ES Legal
Elinar will create virtually any language combination (for example IT/EN) upon request. Lead time for this is approximately 6 weeks. Note: If the use case is for a single language, the performance will be enhanced, if LM is trained with that language only, except in cases where substantial amount of training samples are in another language. Models are able to generalize and transfer knowledge across languages. Good examples of these are Invoice Automation, Sales Order Automation, Certificate Automation and Privacy.
It is possible to focus on specific topic like Legal or Engineering provided that we can acquire topic specific textual data. This will have quite beneficial effect on model performance while analyzing data belonging into pre-trained domain.
In generally Elinar has pretrained models with approximately 220 M, 0.5 B, 1 B and 1.3 B parameters. Pre-trained models are trained with sufficient training data sets, larger data sets being in range of ~50 billion words. For models that use sub-word tokenization this translates to much over 100 billion tokens. Smaller models do not benefit from large data sets as they start underfitting (=model stops learning and start to “forget old data” as it does not have capacity to “remember” more).
Customer Specific LMs
Customer specific LMs are also a very beneficial, but we cannot redistribute them to other customers. It is possible to add up-to a few terabytes of customer specific texts into LM training data. These models will come with a separate cost but will offer enhanced accuracy by being able to pre-learn from the way customer uses language(s). These models also are able to capture business specific knowledge which makes them very powerful when working with use cases within this specific customer.
Language Model effect on Language Understanding
Effect of native language support for the end result is significant. Consider a model (SV/FI/NO/EN) Fine Tuned on Privacy data set with no labelled samples in Portuguese doing not so well on Portuguese Wikipedia page on Clint Eastwood:

Next we use SV/FI/NO/EN/PT/ES (this model has been pretrained on Swedish, Finnish, Norwegian, English, Portuguese and Spanish) LM with the same Fine-Tuning set:
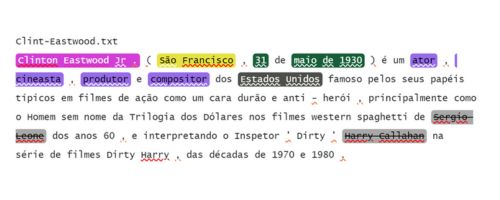
This highlights the power of Deep Transfer Learning, LM is able to generalize from training data set to incredible extent. Human prepared “gold” for this fragment would be:

In this example it is crucial to remember that Fine-Tuning data set did not contain any human prepared samples in Portuguese. Also note that “Harry Callahan” is a fictive character and thus not privacy information.
Speed vs. Accuracy
When considering speed vs. accuracy question there is also a topic of available training data. In general more training data available more feasible it is to use large model. Fine-Tuning large model with very small data set might result in model over fitting (learning samples overly well while loosing ability to generalize). In general the larger the Fine-Tuning set, more feasible it is to use large model underneath.
Model response time is dependent on both model size and length of the response model is generating. This means that 1 B parameter model doing document classification might be faster than 220 M parameter model doing data extraction with long responses. Naturally the same 1 B parameter model will be significantly slower on doing the same data extraction compared to 220 M parameter model.
Model response time is typically not overly important factor when automating business processes. It does not matter if model response time is 8 ms or 800 ms. On the other hand, when doing mass analytics for 500 TB of data this will have time increase of x100. If faster AI takes 6 months to analyze the data, it might not be feasible to run processing with extremely large model. These are important considerations when selecting the size of base model to work with. Another factor is the environmental impact; same workload using larger model uses significantly more computing capacity. When analyzing large datasets, the difference in megawatts can be significant, which obviously have negative impact on environment.
Training Data Clustering
Virtually all real-life use-cases exhibit a phenomenon called training data clustering. This simply means that data set has some type of training data that is much more frequent than some others. This could be visualized as:
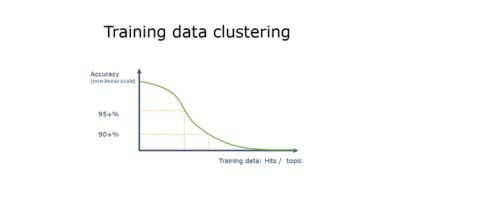
In short this means that model will see much more samples for certain values. For example consider a simple document security classification schema: Public, Internal Use, Restricted, Confidential. If document distribution on training data set is 40/40/19/1 respectively, model will be very good on first three categories, but might struggle with the most important category of “Confidential”. Let’s say training data consist of 1000 samples. This translates to 400 for “Internal Use” and 10 for “Confidential”.
There are several ways to help model to be more accurate on infrequent categories.
Training data elimination and hand-picking
First approach is to eliminate some frequent data form training data set (note: It is much more productive to try to do this on training data selection if humans need to be in-loop on data classification):
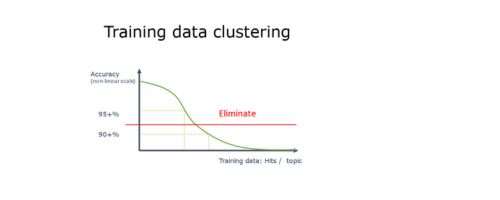
In short this means that we eliminate portion of data from the frequent clusters. In example above we had 400/400/190/10 distribution. When we eliminate 200 documents from first two categories, we end up with 200/200/190/10 distribution that translates roughly to 33/33/32/2 % distribution, which is much more favorable to “Confidential” documents.
Clustering is always a factor that should be estimated during the ontology engineering. If this kind of 40/40/19/1 distribution is estimated, extra care should be given into training data selection. For example, if the result is that top secret will be strongly underrepresented in the data set, it would be beneficial to try to find additional examples to match this category by hand-picking “Confidential” documents into training data set.
Training Data Augmentation
Elinar uses several proprietary techniques to augment training data. One specific method is a way to use existing training data to create similar new pseudo-synthetic training data. This process can be tuned to generate more samples on the infrequent categories. On several cases this has proven to be very effective. Naturally this can not change 10 samples into 30 effective samples, but real-life experiments show that we can get over 10% accuracy increase on infrequent categories based on this method. Unfortunately, we have no UI support for this currently. Contact Elinar Specialists to implement this type of “balanced augmentation” on the backed data preparation routines.
Data Variance
Data Variance can have significant impact on both data extraction and classification accuracy. In this context variance means how different the source data is in regard to training data or how much variance we have within training data. Consider a model with a classification property with values (Vehicles, Weapon Systems, Ammunition, Textiles, Administration) that has been trained to provide “Weapon Systems” when document is somehow related to any type of weapon system. Training has been done with data from the traditional arms manufacturer and is of small variance. Should model encounter a document regarding biological weapons it might not provide accurate classification results as the document is completely out-of-scope regarding the training data.
Strategies for obtaining training data
Most expensive way to obtain training data is to use brute force by humans to label data. In some cases this is the only way to approach this, but there are several ways that may help clients to mitigate the cost.
Extract data from existing systems
Customers usually have existing systems (ERP, DMS and so on) that contain labelled data. In many cases this data can be uploaded to ElinarAI Miner with a simple code. This process includes two steps:
- Data extraction from existing system
- Import to ElinarAI Miner
Both of these steps incur a cost, but in general having pre-populated (with metadata) data set that humans will only validate is much more productive than labelling from scratch. Studies prove that human mind is more effective when trying to find errors than doing bulk labelling work.
Smart data selection
Consider the data distribution (40/40/19/1) from clustering example above. As explained category with only 1% representation will be least accurate in this case. When planning on what data to include in training data it is advisable to use random sampling for a portion (~40-50%) of data that naturally follows this distribution. Other half of the data should be hand picked in a way that will include known projects or cases that will likely have more “Confidential” documents than average. This will affect the distribution of samples to more balanced.
Summary
Field of deep learning has endless possibilities. Elinar has focused on providing our customers most profitable ways to benefit from automation possibilities. We at Elinar have spent significant engineering effort on ensuring cost-effectiveness of Natural Language Understanding implementation.
When training a model, it is crucial to select Language Model that has been trained on properly curated and pseudonymized training data. LM needs to be trained with proper language combinations and with domain data (if available). When selecting fine-tunning data there are strategies to make data more effective on solving the business problem.
With Deep Learning and Deep Transfer Learning anything is possible. Elinar has capabilities and know-how to help our customers and partners to gain utmost out of these possibilities.